
1. 功能简介
本方案利用伙伴云自动化中的“AI文生文”原生能力,结合阿里云通义千问大模型,实现“一键上传 PDF/图片,自动提取信息填入表格”的效果。
- 适用场景: 跨境物流面单、采购发票、合同关键条款提取等。
- 核心优势:
- 零代码: 不用写代码,不用手搓复杂的 JSON 请求体
- 原生集成: 使用伙伴云官方封装的 AI 节点,配置更直观
- 成本低廉: 仅需支付通义千问token费用(单次识别大约几分钱,具体要看模型选择和输出要求)
2. 实现原理:5步闭环
我们将使用新版自动化的两个核心节点类型:【调用服务端API】和 【AI文生文】。
- 上传文件(调用服务端API):把附件传给阿里云,换取
File ID。 - 读取文件内容(AI文生文 - Qwen-Long):让 AI 根据 ID 读取文件全文。
- 结构化解析(AI文生文 - Qwen-Plus):让 AI 把全文按 JSON Schema 规则整理好。
- 写入伙伴云表格(更新数据):把整理好的字段填回表格。
- 删除文件(调用服务端API):清理云端缓存,释放空间。
3. 准备工作
- 阿里云准备:
- 阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台,注册账号,获取 API-KEY。
- 注意: 复制并保存好这个Key,它是连接伙伴云和AI的凭证。
- 伙伴云准备:
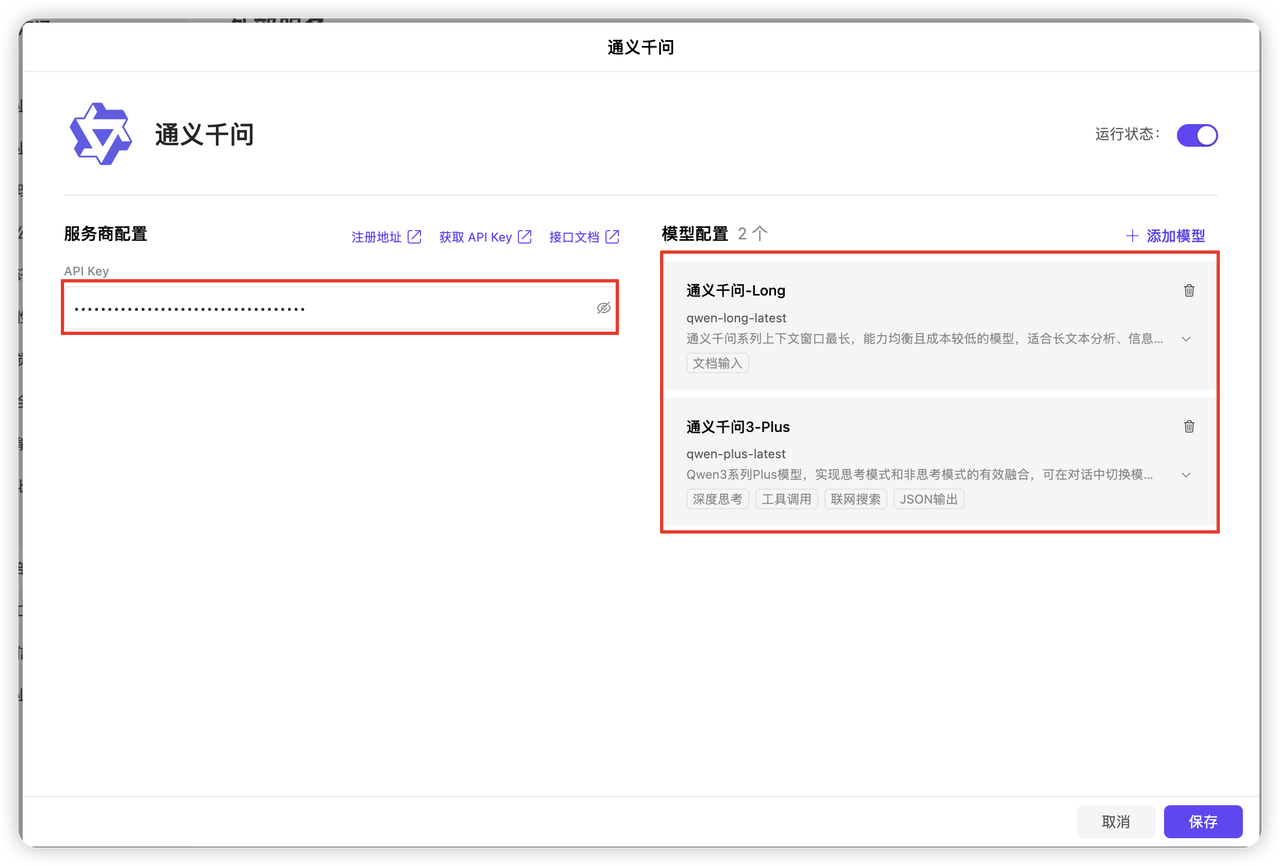
- 企业设置-企业后台-外部服务-AI大模型-添加服务商
- 添加通义千问并将 API Key配置好,添加需要的模型,这里我们用到了 通义千问-Long 和 通义千问3-Plus
4. 详细配置步骤
第一步:创建快捷按钮
- 位置:自动化 → "+" → 创建快捷按钮。
- 设置:按钮名称"AI识别",勾选显示位置(如表格工具栏)。
第二步:上传文件 (获取 File ID)
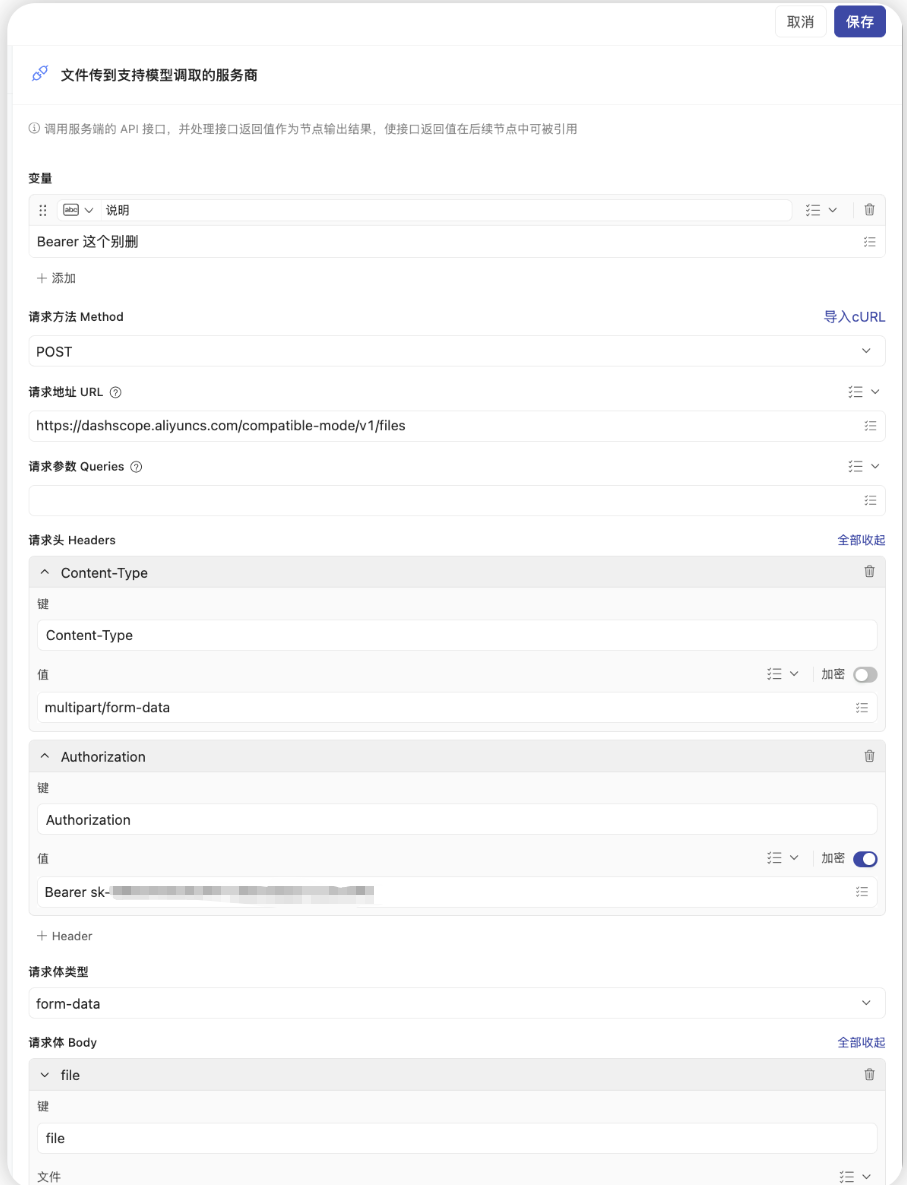
- 节点类型: 调用服务端API (HTTP Request)
- 作用: 将伙伴云的附件链接发送给阿里云,获取文件的唯一标识。(大模型无法直接读取伙伴云的附件链接,需要先将文件传输给它的服务器。)
- 配置细节:
- 请求方法 (Method):
POST - 请求地址 (URL):
https://dashscope.aliyuncs.com/compatible-mode/v1/files(注意:使用 compatible-mode 兼容接口) - 请求头 (Headers):
Content-Type:multipart/form-dataAuthorization:Bearer sk-xxxxxxxx(你的阿里云 API-KEY,建议开启右侧“加密”开关,仅需从sk开始替换,前面的Bearer 不要动)
- 请求体 (Body) - 类型选择
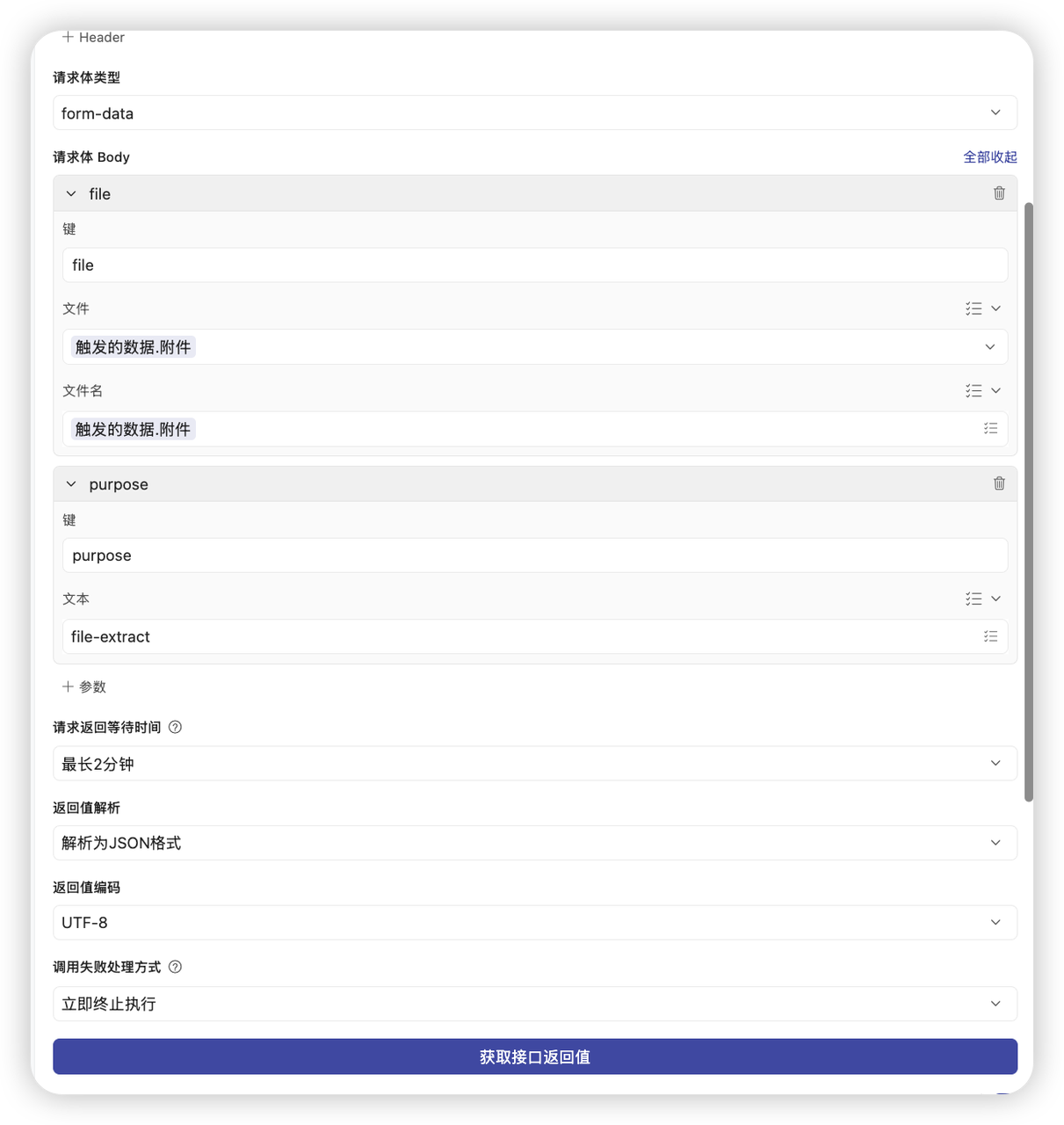
form-data:- 参数1:
- 键 (Key):
file - 文件 (Value): 点击右侧按钮,选择 “触发的数据” > “附件字段”
- 文件名 (Filename): 同样选择 “触发的数据” > “附件字段” (注意:两行都要填)
- 键 (Key):
- 参数2:
- 键 (Key):
purpose - 文本 (Value):
file-extract
- 键 (Key):
- 参数1:
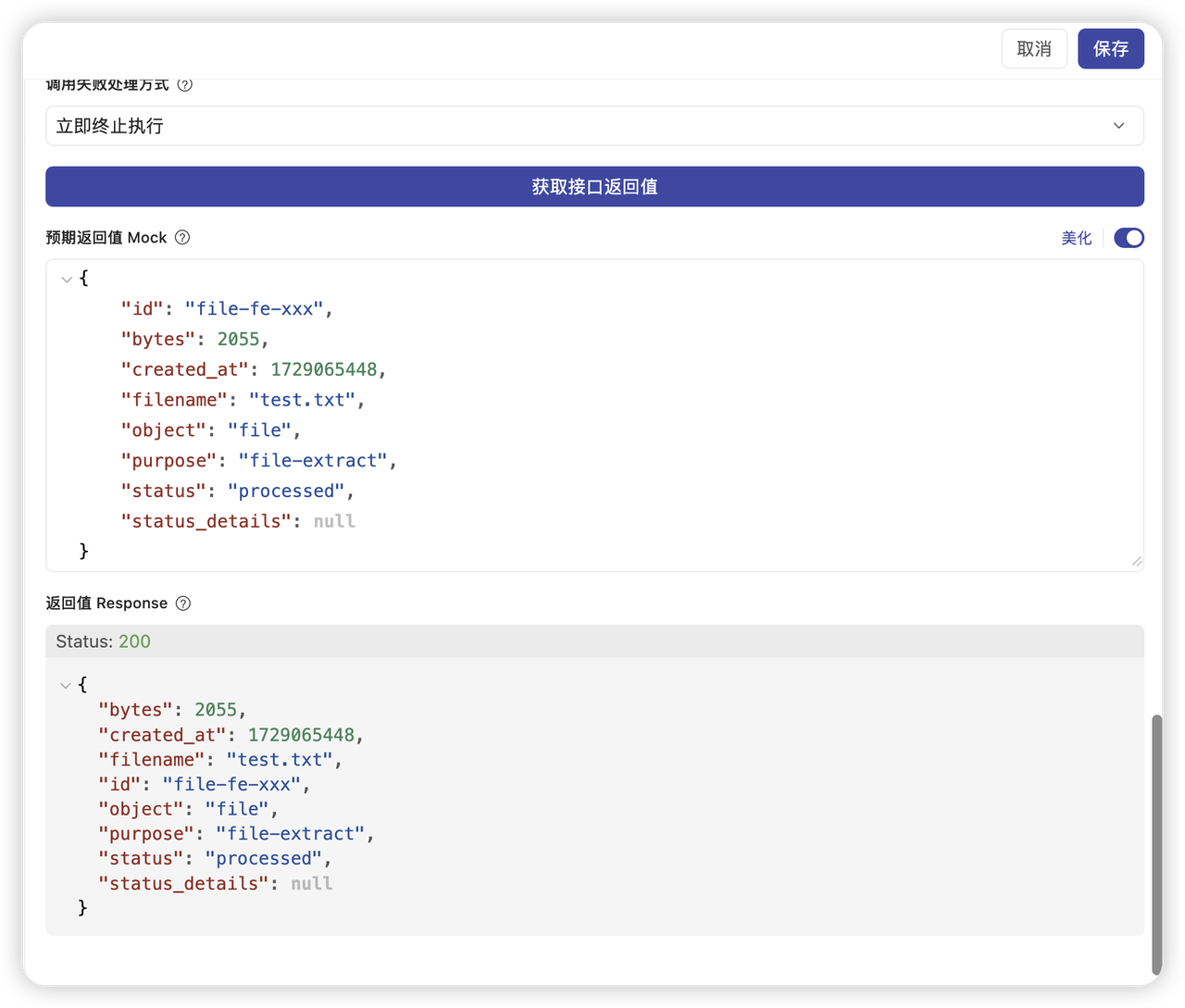
- 返回值设置:
- 解析为 JSON 格式。
- 超时时间建议设为“最长2分钟”。(此后的内容不需要人工配置)
- 请求方法 (Method):
第三步:读取文件内容 (Qwen-Long)
- 节点类型: AI文生文
- 作用: 利用长文本模型,读取上一步上传的文件,并将其转化为文字。
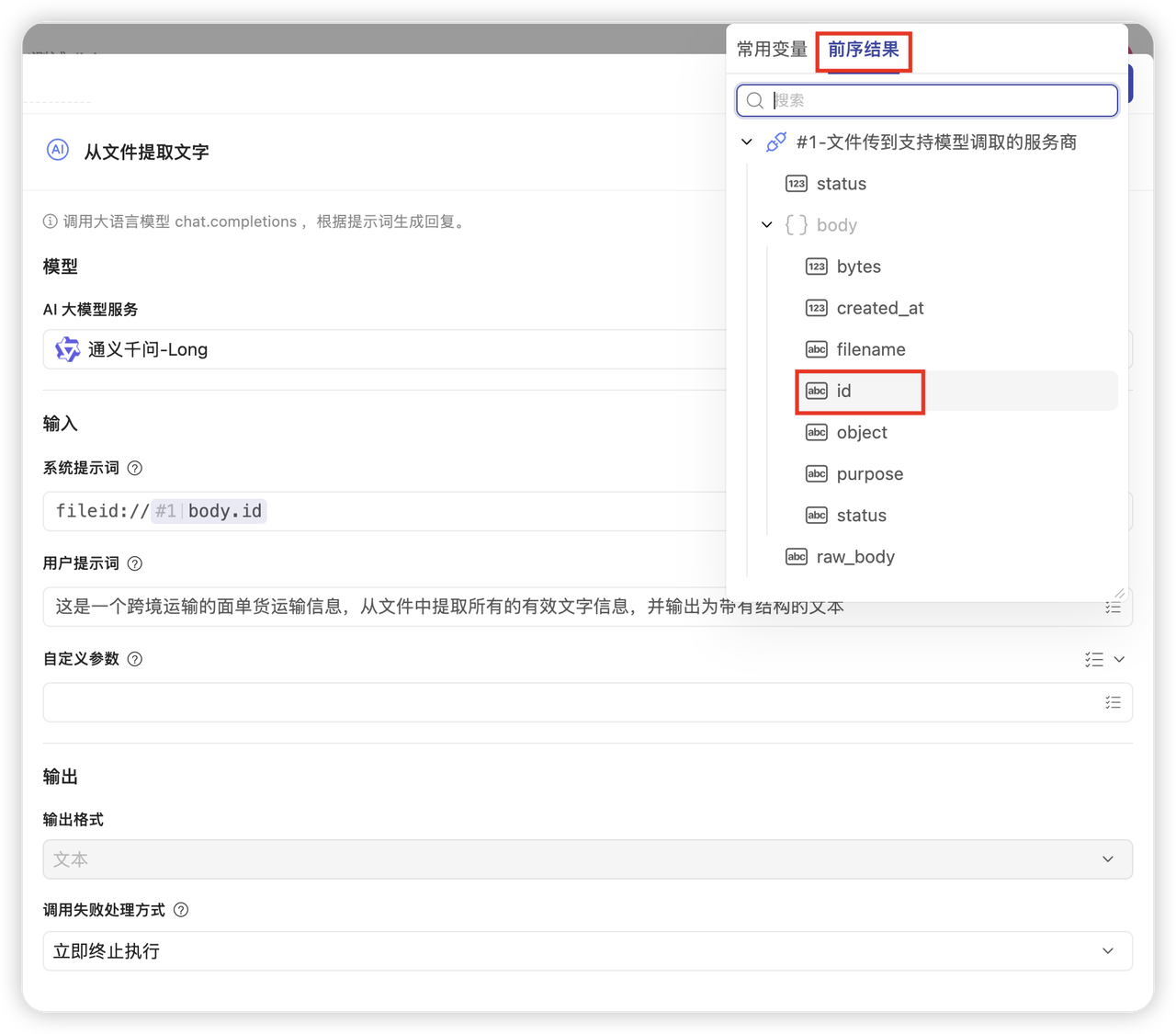
- 配置细节:
- 模型选择: 选择
qwen-long(在准备工作时,如果已经配置好对应模型,那么这里可以直接选择;如果没有在企业中配置,也可以在此处单独配置模型。) - 提示词 (Prompt):
- 系统提示词:fileid://[点击引用第二步输出的 body.id]
fileid://是通义千问识别文件的标准协议头,后面紧跟ID,不要有空格- body.id 指的是在上一步中,返回的JSON中的 文件id值
- 多文件上传时,可以通过 fileid://文件id,fileid://文件id2,来进行拼接
- 文件id传入系统提示词是通义千问的要求,系统提示词(System)代表“环境设定”或“背景知识”,把文件 ID 放在这里,相当于把文件内容“灌输”给了 AI 的大脑背景,然后用户提示词(User)再去提问,AI 就能基于背景流畅作答。
- 用户提示词:按需设计即可
- 比如:这是一个跨境运输的面单货运输信息,从文件中提取所有的有效文字信息,并输出为带有结构的文本
- 原理:这是告诉 AI “读完文件后具体要做什么”
- 系统提示词:fileid://[点击引用第二步输出的 body.id]
- 模型选择: 选择
第四步:结构化解析 (Qwen-Plus + JSON Schema)
- 节点类型: AI文生文
- 作用: 这是最关键的一步! 利用 Plus 模型的逻辑能力,把上一步识别出来的文字,按规则清洗成标准 JSON。
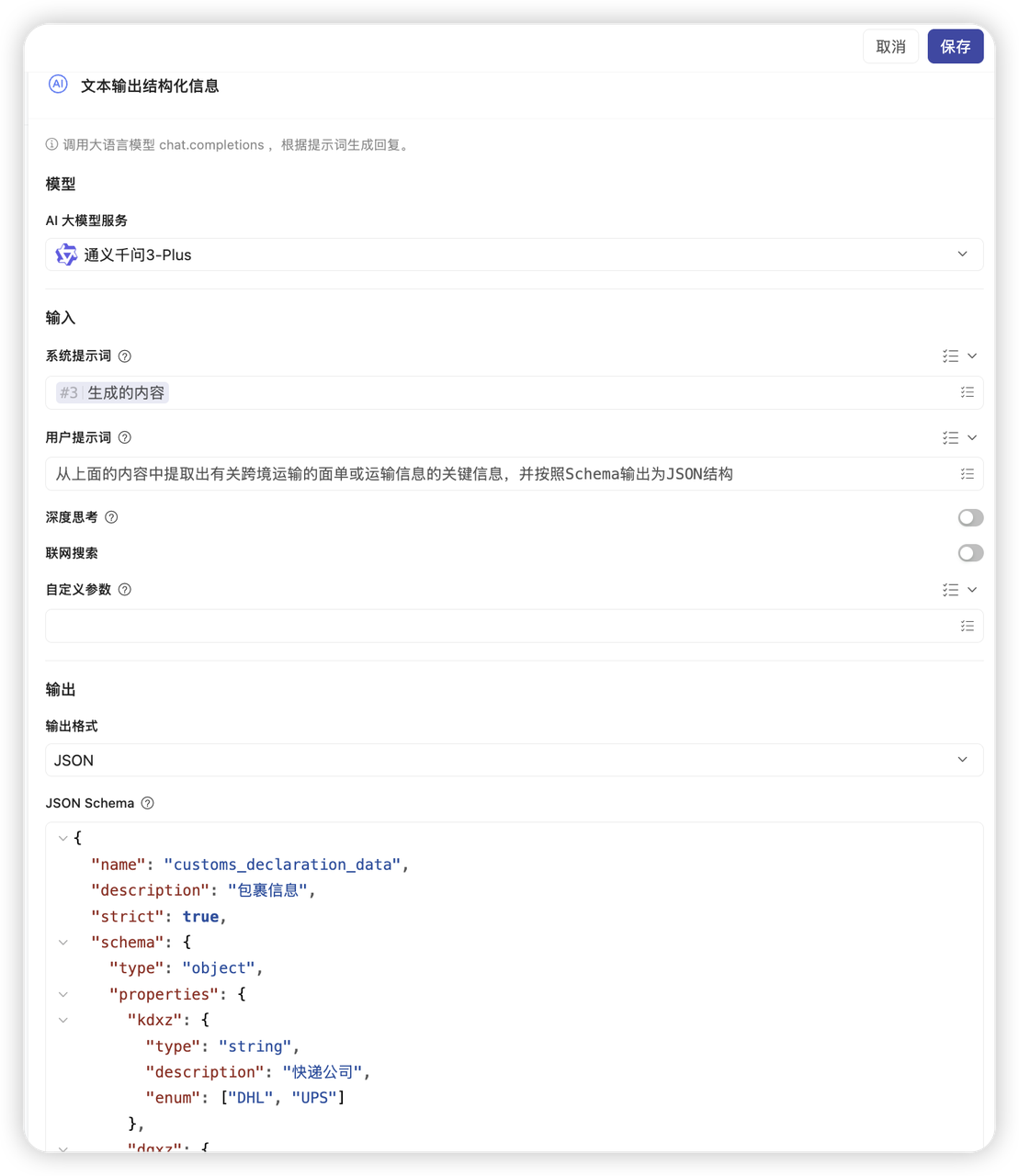
- 配置细节:
- 模型选择: 选择
qwen-plus(适合做逻辑分析)。 - 提示词 (Prompt):
- 系统提示词:上一步生成的内容
- 用户提示词:从上面的内容中提取出有关跨境运输的面单或运输信息的关键信息,并按照Schema输出为JSON结构
- 输出格式:JSON
- JSON Schema:(示例)
{ "name": "extraction_result", "strict": true, "schema": { "type": "object", "properties": { "name": { "type": "string", "description": "收件人名字" }, "number": { "type": "string", "description": "编号" }, "id": { "type": "string", "description": "物流单号" }, "value": { "type": "number", "description": "金额,只要数字,不要货币符号" }, "type": { "type": "string", "enum": ["CNY", "USD"], "description": "统一转为大写代码" }, "list": { "type": "array", "description": "物品明细清单", "items": { "type": "object", "properties": { "englishname": { "type": "string", "description": "物品英文名称" }, "chinesename": { "type": "string", "description": "物品中文名称" }, "amount": { "type": "number", "description": "数量" }, "price": { "type": "string", "description": "单价" } }, "required": ["englishname", "chinesename", "amount", "price"], "additionalProperties": false } } }, "required": ["id", "name", "value", "list", "number", "type"], "additionalProperties": false } } - 模型选择: 选择
第五步:更新数据
- 节点类型:修改已有数据
- 作用: 更新主表数据,这里我们是在触发数据上传文件并点击快捷按钮进行识别,识别结果也写入当前数据
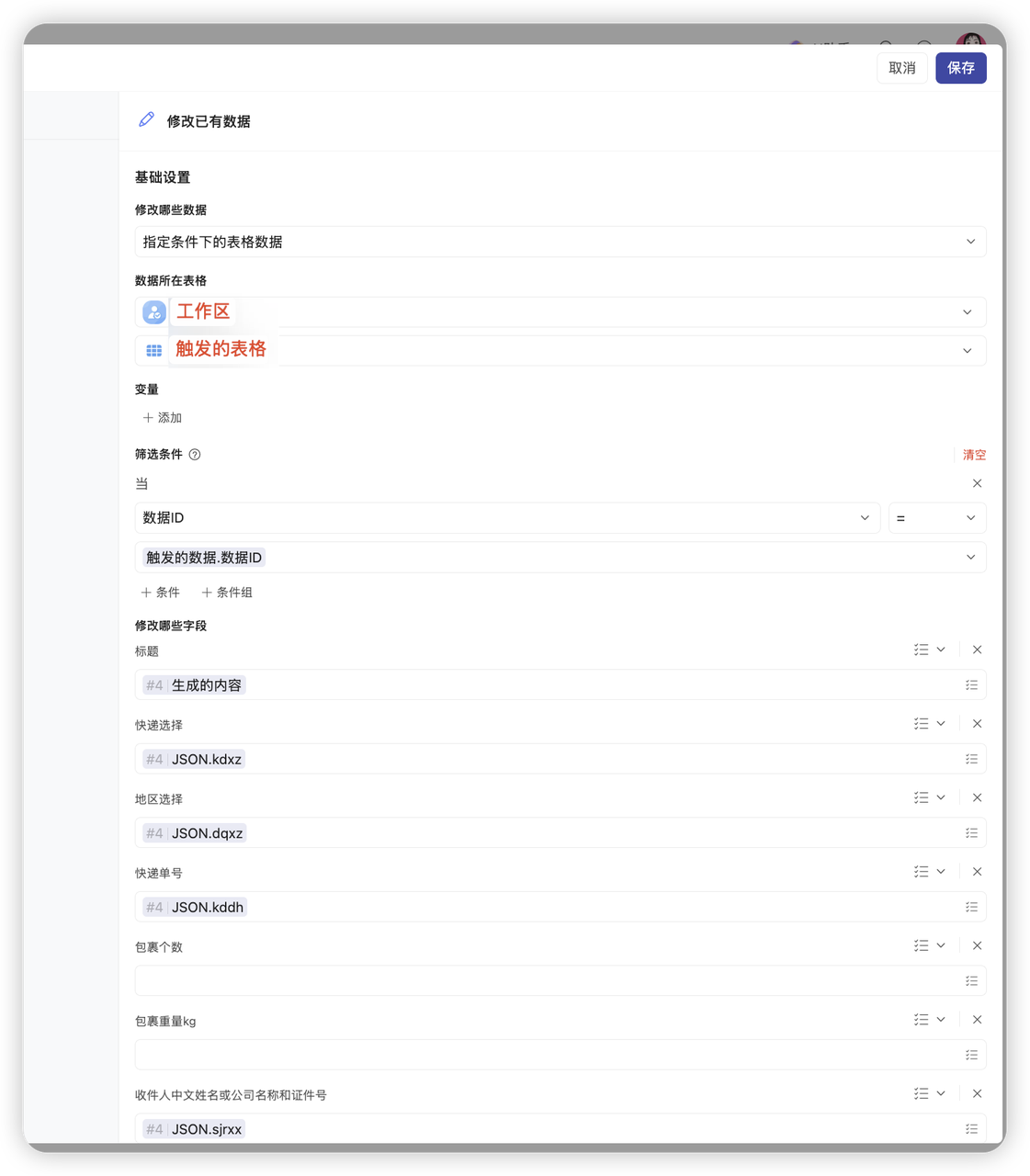
- 配置细节:
- 选择工作区、表格、数据
- 字段赋值:
- 添加需要赋值的字段,并对应选择json中的输出结构,例如:快递单号 = 上一步生成内容中的快递单号
- 赋值时注意字段类型的匹配,比如数值类型字段只能用 json中定义为 number的类型进行赋值
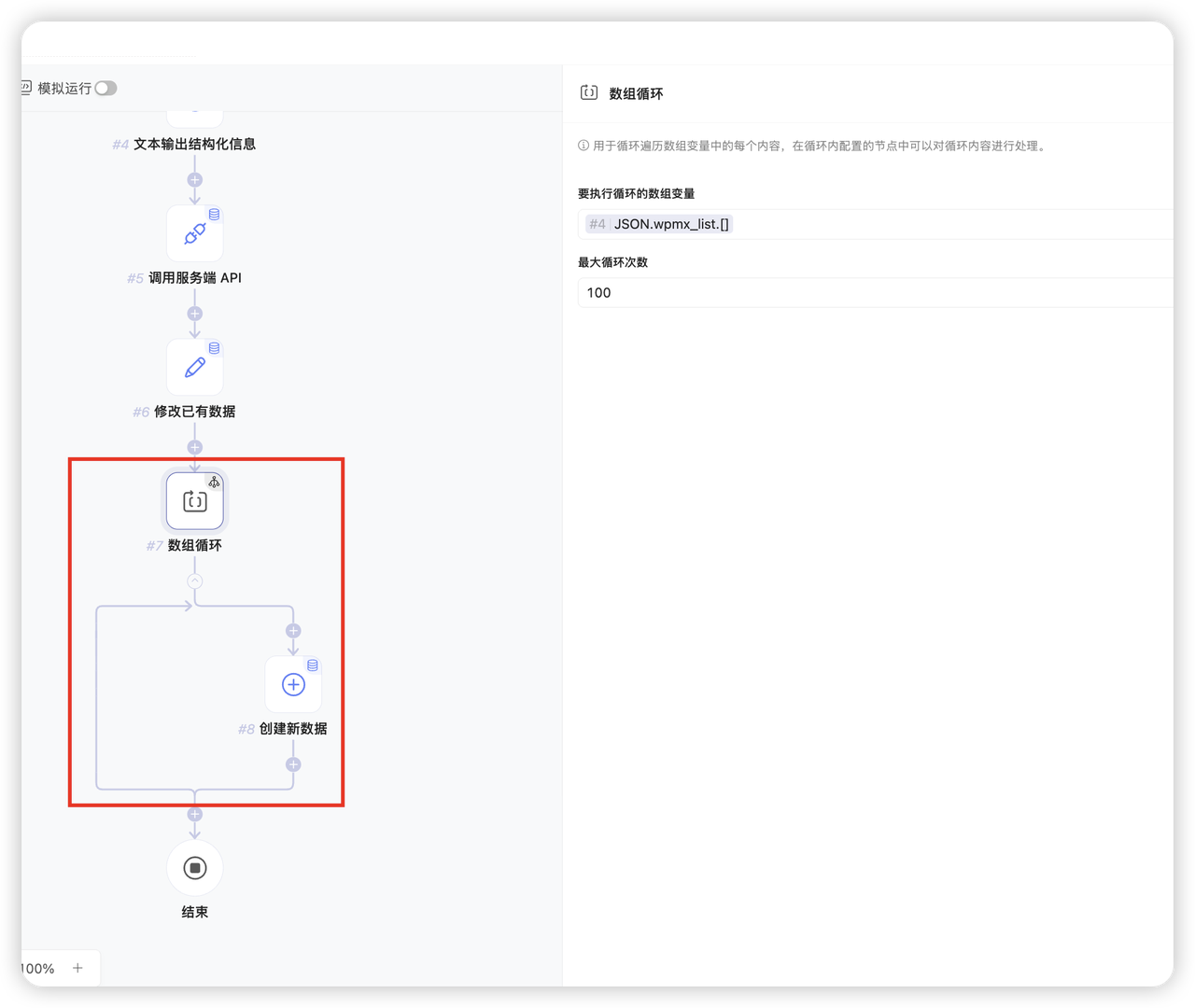
- 如果需要用识别出的明细表向子表赋值,可以用 数组循环 + 创建新数据 节点实现,要执行循环的数组变量选择JSON中定义的数组即可
第六步:删除文件 (释放存储空间)
- 节点类型: 调用服务端API
- 作用: 释放阿里云存储空间。
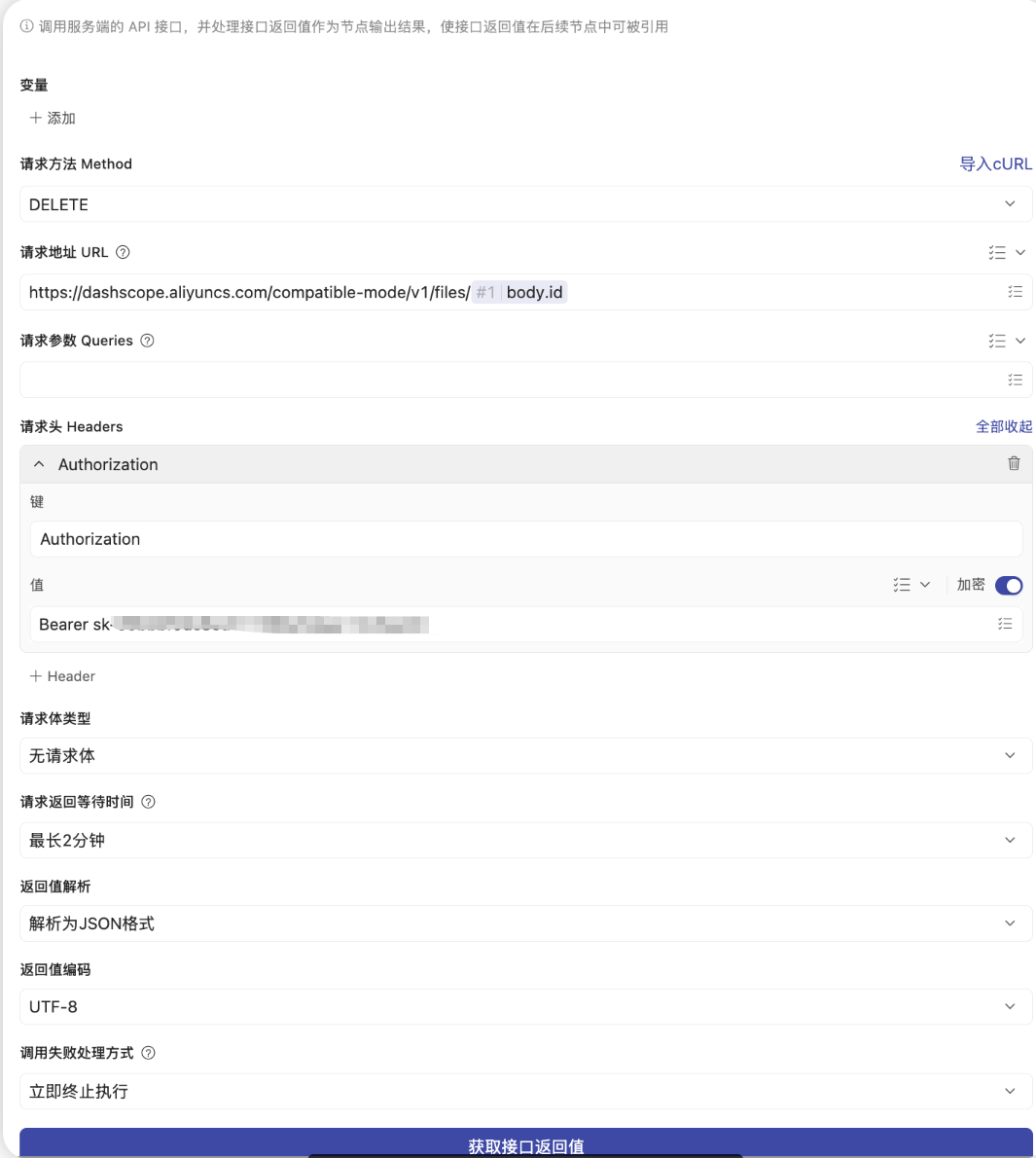
- 配置细节:
- URL:
https://dashscope.aliyuncs.com/api/v1/files/[点击引用第二步的 output.id] - Method:
DELETE - Header:
Authorization: Bearer [你的API-KEY]
- URL:
5. 进阶:如何编写“防呆”的 JSON Schema
在第四步的 Prompt 中,粘贴一个好的 Schema 是成功的关键。它能防止 AI 乱说话。
什么是 JSON Schema?
它是一段代码,用来告诉 AI:“我要一个对象,里面必须有个叫‘金额’的字段,而且必须是数字”。
如何写出你要的JSON Schema?
你可以直接用大白话描述你需要的 字段、类型、描述,然后将内容内的 JSON Schema 示例都输入给AI,让AI快速为你写好一个可以直接粘贴到伙伴云使用的Schema
本案例中的模版示例(请复制修改后贴入第四步 Prompt):
{
"name": "extraction_result",
"strict": true,
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "收件人名字"
},
"number": {
"type": "string",
"description": "编号"
},
"id": {
"type": "string",
"description": "物流单号"
},
"value": {
"type": "number",
"description": "金额,只要数字,不要货币符号"
},
"type": {
"type": "string",
"enum": ["CNY", "USD"],
"description": "统一转为大写代码"
},
"list": {
"type": "array",
"description": "物品明细清单",
"items": {
"type": "object",
"properties": {
"englishname": {
"type": "string",
"description": "物品英文名称"
},
"chinesename": {
"type": "string",
"description": "物品中文名称"
},
"amount": {
"type": "number",
"description": "数量"
},
"price": {
"type": "string",
"description": "单价"
}
},
"required": ["englishname", "chinesename", "amount", "price"],
"additionalProperties": false
}
}
},
"required": ["id", "name", "value", "list", "number", "type"],
"additionalProperties": false
}
}
- 关键参数说明:
"type": "number":强制AI把"200元"转换成200,方便后续计算。"enum": ["CNY", "USD"]:强制AI做选择题,把"RMB"、"¥"统一清洗为"CNY"。"description":给AI的备注,告诉它这个字段的提取规则。
6. 常见问题排查 (FAQ)
Q1:AI 节点报错,提示文件无法读取?
- 检查点: 确认第二步(上传)和第三步(读取)之间是否连接正确。
- 关键点: 第三步的 Prompt 里,
fileid://后面必须紧跟 ID,不能有空格,也不能换行。
Q2:数据没填进去?
- 检查点: 查看自动化的“执行日志”,逐步检查是否完成了执行
- 第三步(Qwen-Long)是否输出的文件的识别结果
- 第四步(Qwen-Plus)输出的是不是纯 JSON。
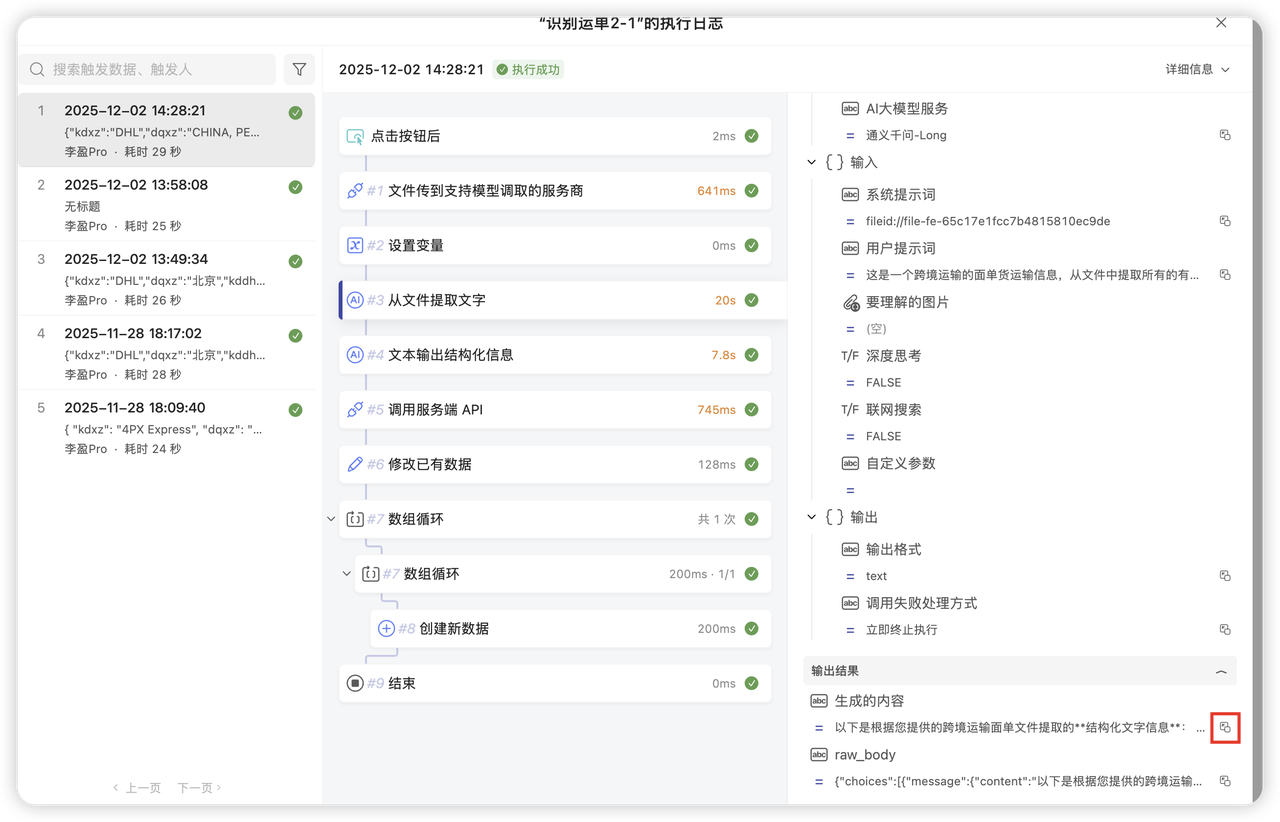
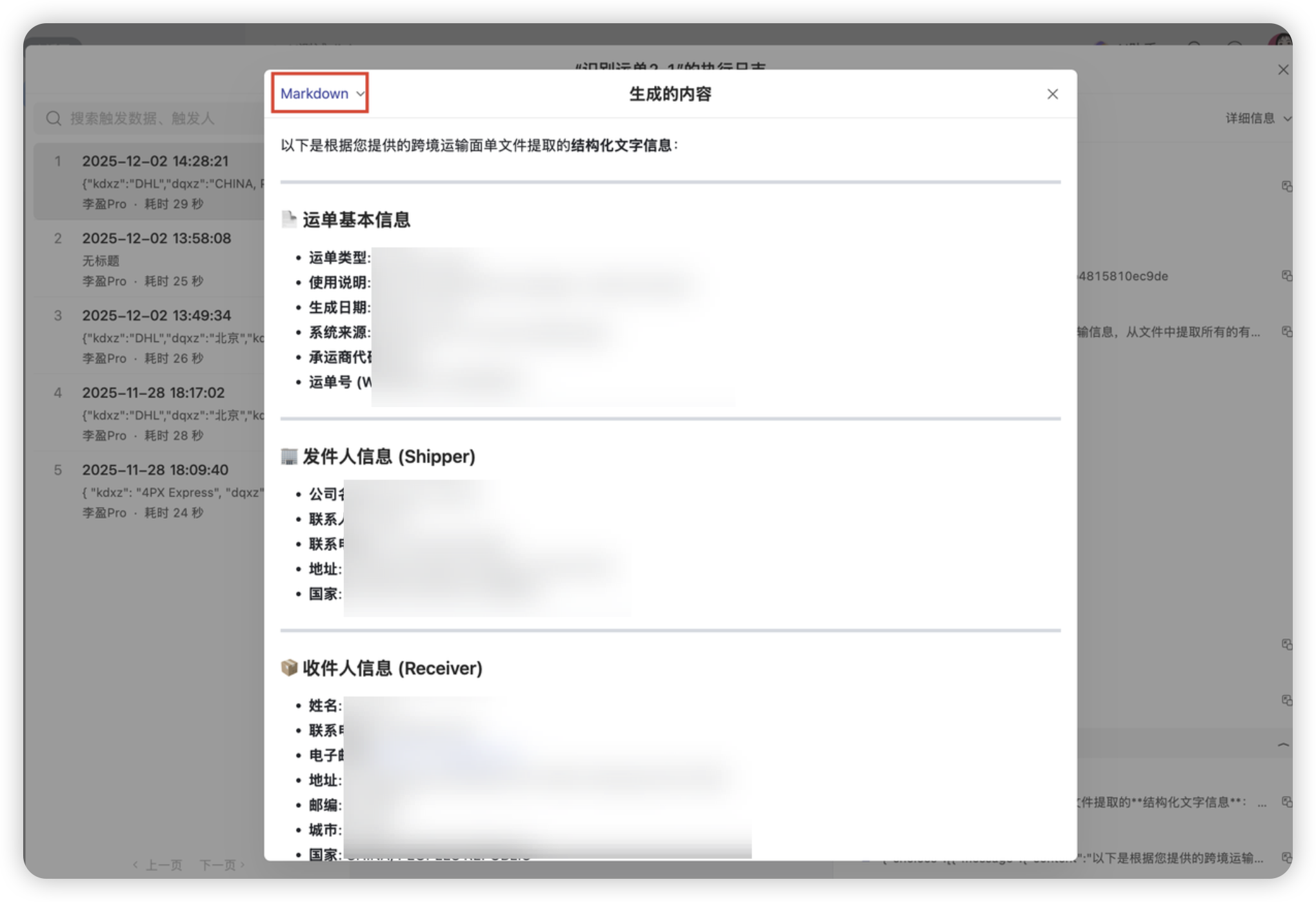
Q3:一定要用两个 AI 节点吗?能合并吗?
- 如果使用通义千问的模型,目前必须分开
Qwen-Long能读超长文件,适合做“搬运工”。Qwen-Plus便宜且逻辑强,能输出JSON,适合做“分析师”。- 组合使用,既省钱(Plus处理纯文本很便宜),效果又好(各司其职)。
Q4:Qwen-Long 是如何处理长文档的?
分为两个步骤:文件上传与 API 调用。详见链接:长上下文(Qwen-Long)